Data Flow in MapReduce Disco Jobs¶
This page describes the dataflows implemented in the MapReduce support of the Disco library. These are implemented in terms of the more general Disco pipeline model.
Disco allows the chaining together of jobs containing map and/or reduce phases. Map and Reduce phases each have their own concepts of data flow. Through combinations of chained jobs, Disco supports a remarkable variety of data flows.
Understanding data flow in Disco requires understanding the core concept of partitioning. Map results in Disco can be either partitioned or non-partitioned. For partitioned output, the results Disco returns are index files, which contain the URLs of each individual output partition:

In the diagrams below, it should be clear when Disco is relying on either reading partitioned input or writing partitioned output.
The overall data flow in a classic Disco job is controlled by four disco.worker.classic.worker.Worker parameters. The presence of map and reduce, determine the overall structure of the job (i.e. whether it is mapreduce, map-only, or reduce-only). The partitions parameter determines whether or not the map output is partitioned, and the number of partitions.
Map Flows¶
The two basic modes of operation for the map phase correspond directly to writing either partitioned or non-partitioned output.

Non-Partitioned Map¶
For non-partitioned map, every map task creates a single output. In other words, the input-output relationship is exactly 1 to 1:

Single-Partition Map¶
Notice that for partitioned output with N partitions, exactly N files will be created for each node, regardless of the number of maps. If the map tasks run on K nodes, exactly K * N files will be created. Whereas for non-partitioned output with M inputs, exactly M output files will be created.
This is an important difference between partitioned output with 1 partition, and non-partitioned output:

The default number of partitions for map is 1. This means that by default if you run M maps on K nodes, you end up with K files containing the results. In older versions of Disco, there were no partitions by default, so that jobs with a huge number of inputs produced a huge number of outputs. If M >> K, this is suboptimal for the reduce phase.
Reduce Flows¶
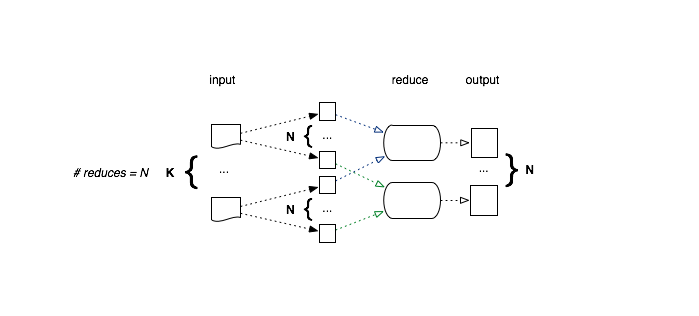
The basic modes of operation for the reduce phase correspond to partitioned/non-partitioned input (instead of output as in the map phase).
Non-Partitioned Reduce¶
For non-partitioned input, there can only ever be 1 reduce task:

The situation is slightly more complicated for partitioned input, as there is a choice to be made whether or not to merge the partitions, so that all results are handled by a single reduce.