The Disco Worker Protocol¶
Note
This protocol is used by a worker in Disco. You don’t need to write your own worker to run a job, you can usually use the standard disco.worker.
A worker is an executable that can run a task, given by the Disco master. The executable could either be a binary executable, or a script that launches other executables. In order to be usable as a Disco worker, an executable needs to implement the The Disco Worker Protocol. For instance, ODisco, which implements the Disco Worker Protocol, allows you to write Disco jobs in the O’Caml language.
There are two parts to using a binary executable as a Disco worker. The first part is the submission of the executable to the Disco master. The second part is the interaction of the executable with its execution environment, when running a task.
This document describes how the worker should communicate with Disco, while it is executing. For more on creating and submitting the job pack, see The Job Pack.
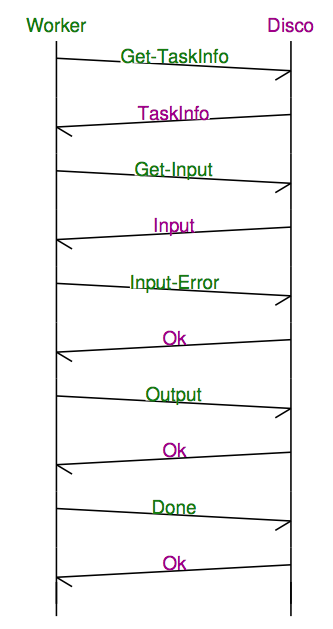
A worker-initiated synchronous message-based protocol is used for this communication. That is, all communication is initiated by the worker by sending a message to Disco, and Disco in turn sends a reply to each message. A worker could pipeline several messages to Disco, and it will receive a response to each message in order.
The worker sends messages over stderr to Disco, and receives responses over stdin. Disco should respond within 600 seconds: it is advised for the worker to timeout after waiting this long.
Note
Workers should not write anything to stderr, except messages formatted as described below. A worker’s stdout is also initially redirected to stderr.
Note
In Python, Workers wrap all exceptions, and everything written to stdout, with an appropriate message to Disco (on stderr). For instance, you can raise a disco.error.DataError to abort the worker and try again on another host. For other types of failures, it is usually best to just let the worker catch the exception.
Message Format¶
Messages in the protocol, both from and to the worker, are in the format:
<name> ‘SP’ <payload-len> ‘SP’ <payload> ‘\n’
where ‘SP’ denotes a single space character, and <name> is one of:
<payload-len> is the length of the <payload> in bytes, and <payload> is a JSON formatted term.
Note that messages that have no payload (see below) actually contain an empty JSON string <payload> = “” and <payload-len> = 2.
Messages from the Worker to Disco¶
WORKER¶
Announce the startup of the worker.
The payload is a dictionary containing the following information:
- “version”
- The version of the message protocol the worker is using, as a string. The current version is “1.1”.
- “pid”
The integer pid of the worker.
The worker should send this so it can be properly killed, (e.g. if there’s a problem with the job). This is currently required due to limitations in the Erlang support for external spawned processes.
The worker should send a WORKER message before it sends any others. Disco should respond with an OK if it intends to use the same version.
TASK¶
Request the task information from Disco.
The worker should send a TASK message with no payload. Disco should respond with a TASK message, and a payload containing the following task information as a dictionary:
- “host”
- The host the task is running on.
- “master”
- The host the master is running on.
- “jobname”
- The name of the job this task is a member of.
- “taskid”
- The internal Disco id of the task.
- “stage”
- The stage of the pipeline this task belongs to.
- “grouping”
- The grouping specified in the pipeline for the above stage.
- “group”
- The group this task will get its inputs from, as computed by the grouping. This is a tuple consisting of an integer label and a host name. Note that due to re-executions, this host name may not match the value in the above “host” field.
- “disco_port”
- The value of the DISCO_PORT setting, which is the port the Disco master is running on, and the port used to retrieve data from Disco and DDFS. This is used to convert URLs with the disco and ddfs schemes into http URLs.
- “put_port”
- The value of the DDFS_PUT_PORT setting. This can be used by the worker to upload results to DDFS.
- “disco_data”
- The value of the DISCO_DATA setting.
- “ddfs_data”
- The value of the DDFS_DATA setting. This can be used to read DDFS data directly from the local filesystem after it has been ascertained that the DDFS data is indeed local to the current host.
- “jobfile”
- The path to the The Job Pack file for the current job. This can be used to access any Additional Job Data that was uploaded as part of the The Job Pack.
INPUT¶
Request input for the task from Disco.
To get the complete list of current inputs for the task, the worker can send an INPUT message with no payload. Disco should respond with an INPUT message, and a payload containing a two-element tuple (list in JSON).
The first element is a flag, which will either be ‘more’ or ‘done’. ‘done’ indicates that the input list is complete, while ‘more’ indicates that more inputs could be added to the list in the future, and the worker should continue to poll for new inputs.
The second element is a list of inputs, where each input is a specified as a four-element tuple:
input_id, status, label, replicaswhere input_id is an integer identifying the input, label is the label attached to the input, and status and replicas follow the format:
status ::= 'ok' | 'busy' | 'failed' replicas ::= [replica] replica ::= rep_id, replica_locationIt is possible for an input to be available at multiple locations; each such location is called a replica. A rep_id is an integer identifying the replica.
The replica_location is specified as a URL. The protocol scheme used for the replica_location could be one of http, disco, dir or raw. A URL with the disco scheme is to be accessed using HTTP at the disco_port specified in the TASK response from Disco. The raw scheme denotes that the URL itself (minus the scheme) is the data for the task. The data needs to be properly URL encoded, for instance using Base64 encoding. The dir is like the disco scheme, except that the file pointed to contains lines of the form
<label> ‘SP’ <url> ‘SP’ <output_size> ‘\n’
The ‘label’ comes from the ‘label’ specified in an OUTPUT message by a task, while the ‘url’ points to a file containing output data generated with that label. The ‘output_size’ specifies the size of the output file.
This is currently how labeled output data is communicated by upstream tasks to downstream ones in the Disco pipeline.
One important optimization is to use the local filesystem instead of HTTP for accessing inputs when they are local. This can be determined by comparing the URL hostname with the host specified in the TASK response, and then converting the URL path into a filesystem path using the disco_data or ddfs_data path prefixes for URL paths beginning with disco/ and ddfs/ respectively.
The common input status will be ‘ok’ - this indicates that as far as Disco is aware, the input should be accessible from at least one of the specified replica locations. The ‘failed’ status indicates that Disco thinks that the specified locations are inaccessible; however, the worker can still choose to ignore this status and attempt retrieval from the specified locations. A ‘busy’ status indicates that Disco is in the process of generating more replicas for this input, and the worker should poll for additional replicas if needed.
It is recommended that the worker attempts the retrieval of an input from the replica locations in the order specified in the response. That is, it should attempt retrieval from the first replica, and if that fails, then try the second replica location, and so on.
When a worker polls for any changes in task’s input, it is preferable not to repeatedly retrieve information for inputs already successfully processed. In this case, the worker can send an INPUT message with an ‘exclude’ payload that specifies the input_ids to exclude in the response. In this case, the INPUT message from the worker should have the following payload:
['exclude', [input_id]]On the other hand, when a worker is interested in changes in replicas for a particular set of inputs, it can send an INPUT message with an include payload that requests information only for the specified input_ids. The INPUT message from the worker in this case should have the following payload:
['include', [input_id]]
INPUT_ERR¶
Inform Disco that about failures in retrieving inputs.
The worker should inform Disco if it cannot retrieve an input due to failures accessing the replicas specified by Disco in the INPUT response. The payload of this message specifies the input and the failed replica locations using their identifiers, as follows:
[input_id, [rep_id]]If there are alternative replicas that the worker can try, Disco should respond with a RETRY message, with a payload specifying new replicas:
[[rep_id, replica_location]]If there are no alternatives, and it is not possible for Disco to generate new alternatives, Disco should reply with a FAIL message (which has no payload).
If Disco is in the process of generating new replicas, it should reply with a WAIT message and specify an integer duration in seconds in the payload. The worker should then poll for any new replicas after the specified duration.
MSG¶
Send a message (i.e. to be displayed in the ui).
The worker can send a MSG message, with a payload containing a string. Disco should respond with an OK.
OUTPUT¶
The worker should report its output(s) to Disco.
For each output generated by the worker, it should send an OUTPUT message specifying the type and location of the output, and its label:
[label, output_location, output_size]Local outputs have locations that are paths relative to jobhome.
DONE¶
Inform Disco that the worker is finished.
The worker should only send this message (which has no payload) after syncing all output files, since Disco normally terminates the worker when this message is received. The worker should not exit immediately after sending this message, since there is no guarantee if the message will be received by Disco if the worker exits. Instead, the worker should wait for the response from Disco (as it should for all messages).
ERROR¶
Report a failed input or transient error to Disco.
The worker can send a ERROR message with a payload containing the error message as a string. This message will terminate the worker, but not the job. The current task will be retried by Disco. See also the information above for the DONE message.
FATAL¶
Report a fatal error to the master.
The worker can send an FATAL message, with a payload containig the error message as a string. This message will terminate the entire job. See also the information above for the DONE message.
PING¶
No-op - always returns OK.
Worker can use PING as a heartbeat message, to make sure that the master is still alive and responsive.
Messages from Disco to the Worker¶
OK¶
A generic response from Disco. This message has the payload “ok”.
FAIL¶
A possible response from Disco for an INPUT_ERR message, as described above.
RETRY¶
A possible response from Disco for an INPUT_ERR message, as described above.
WAIT¶
A possible response from Disco for an INPUT_ERR message, as described above.
Sessions of the Protocol¶
On startup, the worker should first send the WORKER message, and then request the TASK information. The taskid and mode in the TASK response can be used, along with the current system time, to create a working directory within which to store any scratch data that will not interact with other, possibly concurrent, workers computing other tasks of the same job. These messages can be said to constitute the initial handshake of the protocol.
The crucial messages the worker will then send are the INPUT and OUTPUT messages, and often the INPUT_ERR messages. The processing of the responses to INPUT and INPUT_ERR will be determined by the application. The worker will usually end a successful session with one or more OUTPUT messages followed by the DONE message. Note that it is possible for a successful session to have several INPUT_ERR messages, due to transient network conditions in the cluster as well as machines going down and recovering.
An unsuccessful session is normally ended with an ERROR or FATAL message from the worker. An ERROR message terminates the worker, but does not terminate the job; the task will possibly be retried on another host in the cluster. A FATAL message, however, terminates both the worker, and the entire job.
Considerations when implementing a new Worker¶
You will need some simple and usually readily available tools when writing a new worker that implements the Disco protocol. Parsing and generating messages in the protocol requires a JSON parser and generator. Fetching data from the replica locations specified in the Disco INPUT responses will need an implementation of a simple HTTP client. This HTTP client and JSON tool can also be used to persistently store computed results in DDFS using the REST API. Optionally, there is support to use the Disco master itself to save job-results to DDFS, using the save_results field in the jobdict.
The protocol does not specify the data contents of the Disco job inputs or outputs. This leaves the implementor freedom to choose an appropriate format for marshalling and parsing data output by the worker tasks. This choice will have an impact on how efficiently the computation is performed, and how much disk space the marshalled output uses.